先前在 Day4 提到的吞吐量 (Throughput) 🚀 是伺服器在一定時間內可以處理的請求數量。透過增加吞吐量,可以同時為用戶提供更多服務,從而提高整體系統效能。
而Batching就是同時處理多個user request來提高吞吐量的基本方法。它的基本概念是將多個input request組成一個batch,然後同時處理這個batch中的所有項目,而不是一個一個地逐一處理。它同時也是最簡單提高GPU使用率的方式 🖥️,直接一口氣設定大的batch,一次收集多一點的輸入進行處理,可以減少參數載入的頻率。
🔍 簡單來說它的優點如下:
- 可以提高GPU計算效率 ⚡
- 減少I/O花費 💾
- 增加吞吐量 📊
如果沒有設定Batch,就是一次只能處理一個請求,導致資源的浪費。

(圖源: 自製)
不過設定batch也要考慮自己VRAM可負荷的範圍喔! 🧠💡
最傳統的方法是設定一個固定值,這就是Static Batching。
但是LLM每次request的長度不一樣,也不知道每個request會產生多少tokens,在一個batch當中,有可能出現較短的request已經完成,而較長的request仍在推理當中。長的request一直卡著GPU不放,需要等待他全部完成後才會回傳結果。當遇到長度差異越大的request,這個現象會更明顯,這會導致GPU的使用率降低。
如下圖,第三個request在兩回合跌代就結束了,但它還是要等第二個request慢慢生成。
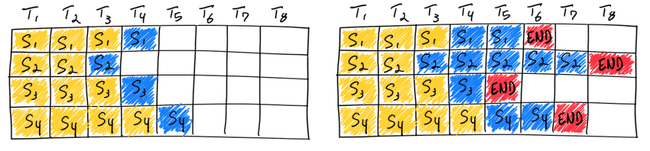
(圖源:anyscale,黃色:pre-fill(input tokens),藍色和紅色:decoding(生成的tokens))
為了解決靜態批次的問題,Orca: A Distributed Serving System for Transformer-Based Generative Models提出了Continuous Batching的方法。它不會在開始下一個batch之前等待所有batch完成,而是在batch當中的其中一個request已經被完成之後,就可以再它的位置調度新的request過去,增加了整體GPU的使用率。
如下圖,雖然乍看第一、三、四個request好像會遇到記憶體會不足的問題,但實際上因為到T8時,前面第一批request已經都到達了END,資源被釋放出來了,而總預留的記憶體通常是這個模型KV快取所需的最大數量tokens (max_tokens),所以並不會遇到生成不了的問題,這也是Continuous Batching的設計厲害的地方。
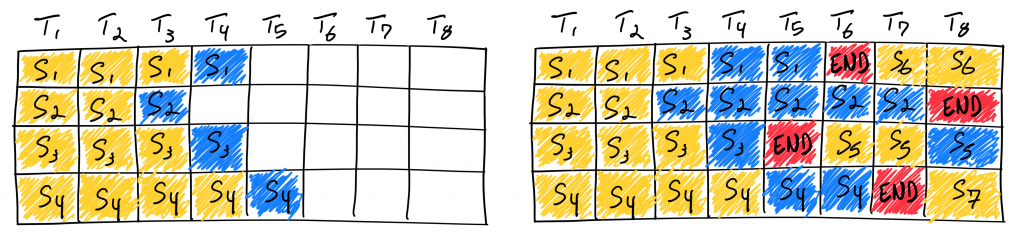
(圖源:anyscale)
不過這看似簡單的原理,實際應用上還是有一個缺點,就是它記憶體預留策略的問題,正是因為Continuous Batching會為KV快取保留max_tokens的記憶體,這代表除非requests都產生大量tokens,否則大部分預留的記憶體將不會被使用到。
vLLM blog 提到他們發現有系統因為記憶體碎片 (fragmentation)和過度預留而浪費了60% - 80%的記憶體。

(圖源: 論文 (Kwon et al., 2023))
如上圖,request A的最大序列長度為2048,request B的最大序列長度為512。這會出現三種類型的記憶體浪費:
其中,Reserved是為了確保request生成的穩定性,預留整個記憶體區塊,即使還沒使用的部分也不能被其他request利用;Internal Fragmentation是因系統不知道模型會產生多少個tokens而過度預留max_tokens而未使用的記憶體;External Fragmentation 是指當固定大小的記憶體區塊與不同長度的序列不匹配時,由記憶體分配器(memory allocator)造成的、無法利用的分散記憶體空間。
🔍 GPT4o的簡單比較:
外部碎片:想像你有一個抽屜,裡面有很多固定大小的小隔間。如果你放進不同大小的物品,某些隔間可能只能部分放滿,剩下的空間無法放入其他物品,這就是外部碎片。
內部碎片:同樣的抽屜裡,你分配了一個較大的隔間來放某個物品,但這個物品只占用了一部分空間,剩下的空間雖然已被劃分給這個物品,卻沒有被充分利用,這就是內部碎片。
而這個問題的解法會在下一章的記憶體管理PagedAttention被介紹到。📚✨
這章節介紹了不同的Batching方式,也介紹了在LLM推理應用中常常看到的Continuous Batching,它夠加快request的處理速度,因為它允許batch當中的部分request提前處理完成,但由於它會預留大量記憶體,可能會有空間浪費,因此後續的實作可以在vLLM框架中體驗搭配PagedAttention輔助的效果,讓記憶體的分配更靈活。
How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
https://www.anyscale.com/blog/continuous-batching-llm-inference
LLM Inference: Continuous Batching and PagedAttention
https://insujang.github.io/2024-01-07/llm-inference-continuous-batching-and-pagedattention/


 iThome鐵人賽
iThome鐵人賽